Inside X’s Open-Source Recommendation Algorithm: What Content Actually Wins Attention?
On the afternoon of January 20, X open-sourced its latest recommendation algorithm.
Musk commented: “We know this algorithm is dumb and still needs major improvements, but at least you can see us working to improve it in real time. Other social platforms wouldn’t dare to do this.”
His statement has two points. First, he admits the algorithm’s shortcomings. Second, he uses transparency as a key selling point.
This is the second time X has open-sourced its algorithm. The 2023 version had gone three years without updates and was already disconnected from the production system. This time, the codebase was completely rewritten. The core model shifted from traditional machine learning to the Grok transformer. According to the official description, “manual feature engineering has been completely eliminated.”
In simple terms: the previous algorithm relied on engineers manually adjusting parameters. Now, AI directly analyzes your interaction history to decide whether to promote your content.
For content creators, this means strategies like “optimal posting times” or “which tags grow followers” may no longer be effective.
We also reviewed the open-source GitHub repository and, with AI’s help, found some hard-coded logic in the code that’s worth exploring.
Algorithm Logic Shift: From Manual Rules to AI-Driven Judgment
First, let’s clarify the differences between the old and new versions to avoid confusion in the discussion that follows.
In 2023, Twitter’s open-source algorithm was called Heavy Ranker. It was fundamentally traditional machine learning. Engineers manually defined hundreds of features: whether a post included images, the author’s follower count, how long ago it was posted, whether it contained links, and so on.
Each feature was assigned a weight, which was continuously tweaked to find the most effective combination.
This new open-source version is called Phoenix. Its architecture is entirely different—think of it as an algorithm that relies much more on large AI models. The core uses the Grok transformer, the same type of technology behind ChatGPT and Claude.
The official README is clear: “We have eliminated every single hand-engineered feature.”
The old rule-based system that relied on manually extracted content features is completely gone.
So, what does the algorithm use to judge whether content is good?
The answer: your behavioral sequence. What you’ve liked, who you’ve replied to, which posts you lingered on for over two minutes, which types of accounts you’ve blocked. Phoenix feeds these behaviors to the transformer, letting the model learn and summarize the patterns.
To illustrate: the old algorithm was like a manually created scorecard, assigning points for each checked box.
The new algorithm is like an AI that has access to your entire browsing history, predicting what you’ll want to see next.
For creators, this means two things:
First, tactics like “best posting time” or “golden tags” now have much less value. The model no longer looks at fixed features, but at each user’s personal preferences.
Second, whether your content gets promoted depends more on “how users react to your content.” These reactions are quantified into 15 types of behavioral predictions, which we’ll detail next.
The Algorithm Predicts 15 Types of User Reactions
When Phoenix evaluates a post for recommendation, it predicts 15 possible user actions:
- Positive actions: like, reply, repost, quote repost, click the post, click the author’s profile, watch more than half a video, expand an image, share, dwell for a certain time, follow the author
- Negative actions: select “not interested,” block the author, mute the author, report
Each action has a predicted probability. For example, the model might estimate a 60% chance you’ll like a post and a 5% chance you’ll block the author.
The algorithm then multiplies each probability by its corresponding weight and sums them to get a final score.
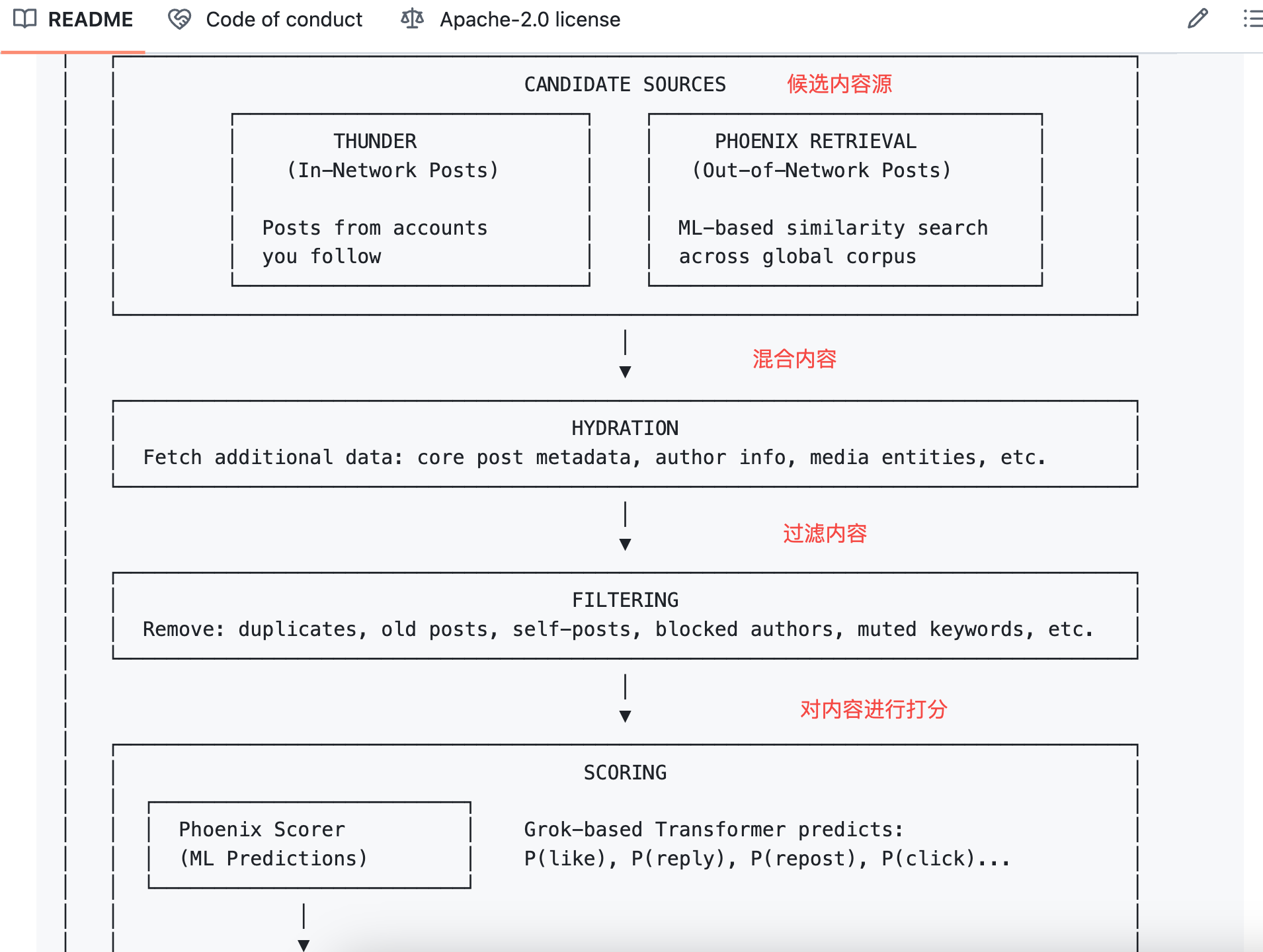
The formula is:
Final Score = Σ ( weight × P(action) )
Positive actions have positive weights; negative actions have negative weights.
Posts with higher total scores are ranked higher; those with lower scores are pushed down.
In practical terms, whether content is “good” is no longer determined by its intrinsic quality alone (though readability and value are still prerequisites for sharing). Instead, it’s determined by “the reactions your content provokes.” The algorithm doesn’t care about the content itself; it cares about user behavior.
With this logic, in extreme cases, a low-quality post that triggers lots of replies might score higher than a high-quality post with no engagement. This may be the system’s underlying logic.
However, the new open-source algorithm doesn’t disclose the exact weights for each behavior, but the 2023 version did.
Old Version Reference: One Report = 738 Likes
Let’s look at the 2023 data set. While it’s outdated, it helps illustrate how the algorithm values different actions.
On April 5, 2023, X publicly released a set of weight data on GitHub.
Here are the numbers:
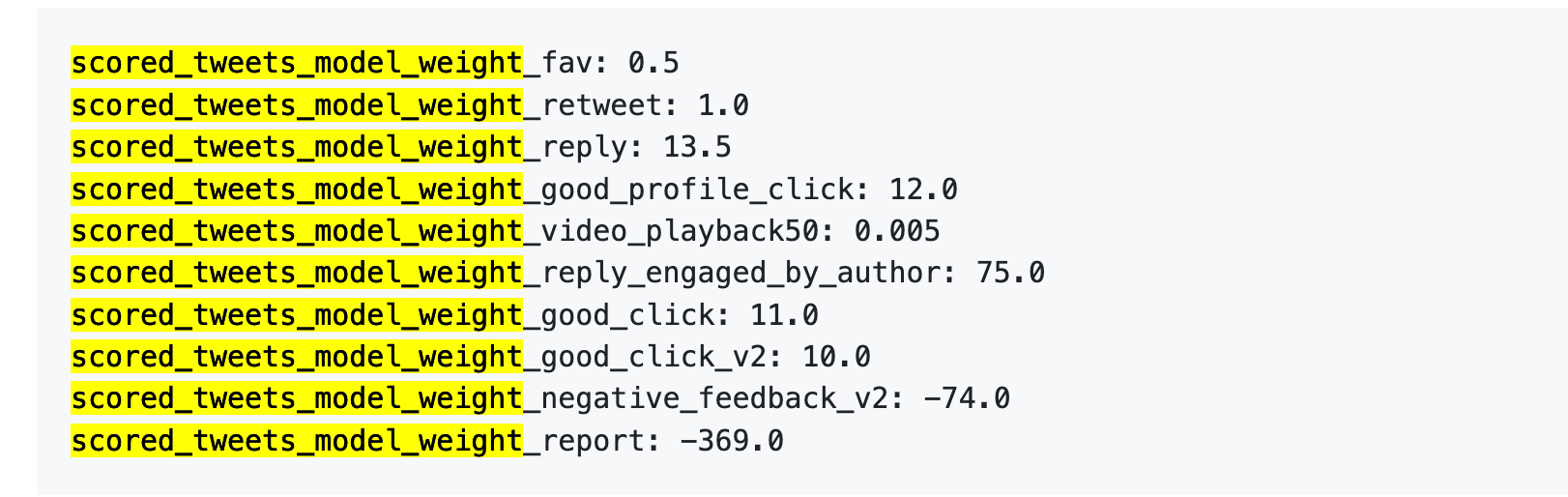
To put it plainly:
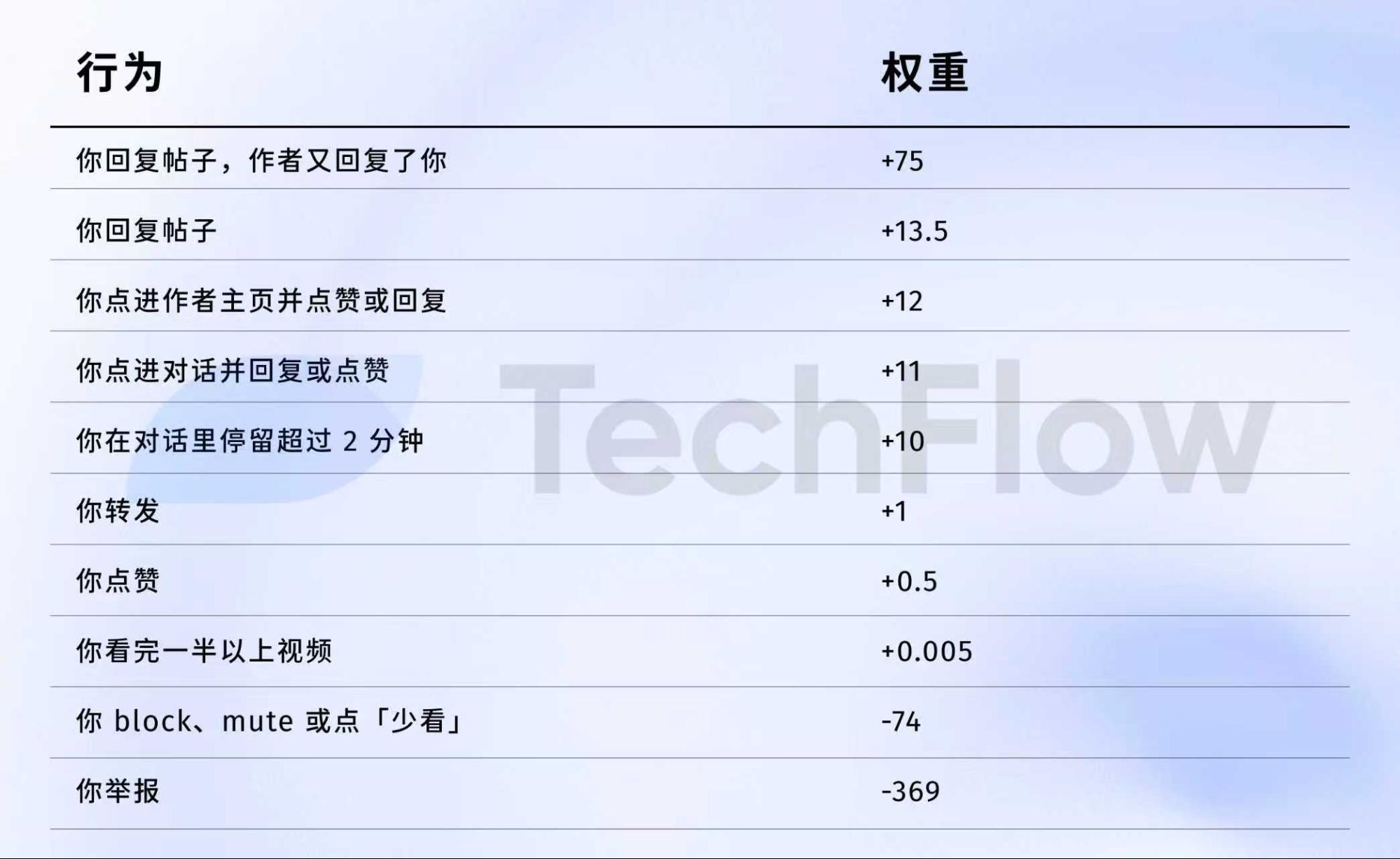
Data source: Old version GitHub twitter/the-algorithm-ml repository. Click to view the original algorithm.
Several numbers are worth noting:
First, likes are nearly worthless. The weight is just 0.5, the lowest among positive actions. The algorithm considers a like nearly valueless.
Second, conversation is what matters. “You reply and the author replies back” has a weight of 75—150 times more than a like. The algorithm values two-way conversations far more than simple likes.
Third, negative feedback carries a steep penalty. One block or mute (-74) requires 148 likes to offset. One report (-369) requires 738 likes. These negative scores accumulate in your account’s reputation, affecting future post distribution.
Fourth, video completion rate is weighted extremely low—just 0.005, almost negligible. This is in sharp contrast to platforms like TikTok, which treat completion rate as a core metric.
The official document also states: “The exact weights in the file can be adjusted at any time… Since then, we have periodically adjusted the weights to optimize for platform metrics.”
The weights can be changed at any time—and they have been.
The new version doesn’t disclose specific values, but the logic framework in the README is the same: positive actions add points, negative actions subtract, and the final score is a weighted sum.
The exact numbers may change, but the relative order is likely unchanged. Replying to someone else’s comment is more valuable than getting 100 likes. Being blocked is worse than getting no interaction at all.
What Should Creators Do with This Information?
After reviewing both the new and old Twitter algorithm code, here are some actionable takeaways:
1. Reply to your commenters. In the weights table, “author replies to commenter” is the highest-scoring action (+75), 150 times more valuable than a like. You don’t need to solicit comments, but always reply if someone comments—even a simple “thank you” is counted by the algorithm.
2. Avoid making users want to block you. One block requires 148 likes to offset. Controversial content may drive engagement, but if that engagement is “this person is annoying, block,” your account’s reputation will take a long-term hit, affecting all future post distribution. Controversy is a double-edged sword—think before you provoke.
3. Put external links in the comments. The algorithm doesn’t want users leaving the platform. Including links in the main text will be penalized—Musk has publicly confirmed this. If you want to drive traffic, put your main content in the post and the link in the first comment.
4. Don’t spam. The new code includes an Author Diversity Scorer, which penalizes consecutive posts by the same author. The intent is to diversify users’ feeds, so it’s better to post one quality piece than ten in a row.
6. There’s no longer a “best posting time.” The old algorithm used “posting time” as a manual feature, but Phoenix has eliminated it. Phoenix only looks at user behavior, not post timing. So those “Tuesday at 3 p.m.” strategies are less relevant than ever.
These are what can be gleaned from the code.
There are also bonus and penalty rules in X’s public documentation that aren’t in this open-source release: blue check verification boosts reach, all-caps posts are penalized, and sensitive content triggers an 80% reduction in reach. These rules aren’t open-sourced, so they’re not covered here.
Overall, this open-source release is substantial.
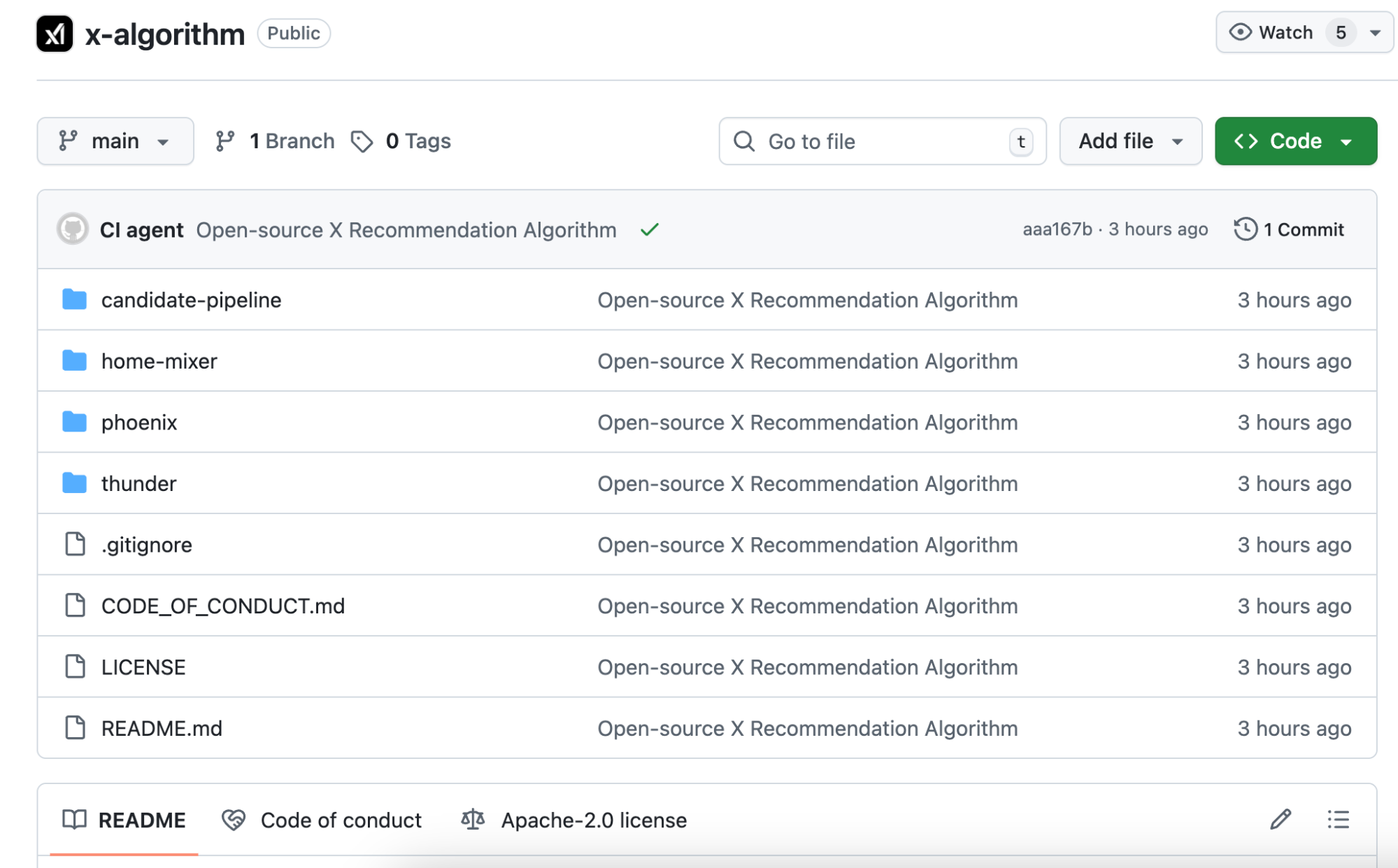
The full system architecture, candidate content recall logic, scoring and ranking process, and various filters are all included. The code is primarily in Rust and Python, with a clear structure and a README more detailed than many commercial projects.
However, some key elements are missing.
1. Weight parameters are not public. The code only explains that “positive actions add points, negative actions subtract,” but doesn’t specify how much a like or block is worth. The 2023 version at least disclosed the numbers; this time, only the formula framework is available.
2. Model weights are not public. Phoenix uses the Grok transformer, but the model parameters aren’t included. You can see how the model is called, but not its internal workings.
3. Training data isn’t public. It’s unclear what data was used to train the model, how user behavior was sampled, or how positive and negative samples were constructed.
In other words, this open-source release tells you “we use weighted sums to calculate scores,” but not the actual weights; it tells you “we use transformers to predict behavioral probabilities,” but not what the transformer looks like inside.
By comparison, TikTok and Instagram haven’t released even this much. X’s open-source release is indeed more comprehensive than other major platforms, but it’s still not fully transparent.
That doesn’t mean open-sourcing isn’t valuable. For creators and researchers, being able to review the code is better than having no access at all.
Statement:
- This article is reprinted from [TechFlow], with copyright belonging to the original author [David]. If you have any concerns regarding this reprint, please contact the Gate Learn team, and the team will handle it promptly according to relevant procedures.
- Disclaimer: The views and opinions expressed in this article are those of the author alone and do not constitute investment advice.
- Other language versions of this article are translated by the Gate Learn team. Without explicit mention of Gate, do not copy, distribute, or plagiarize the translated article.
Share


Related Articles

XRP Surge, A Review of 9 Projects with Related Ecosystems

Pump.fun Launches Its Own AMM Pool? The Intent to Take Raydium’s Profits is Obvious

Every U.S. Crypto ETF You Need to Know About in 2025

Reviewing The History Of Crypto Market Crashes: Every Panic Is Said To Be The Last One

The Rise and Outlook of Next-Generation AI Cryptocurrencies
