В открытом алгоритме рекомендаций X: какой контент на самом деле привлекает внимание?
Днем 20 января X открыла исходный код своего нового рекомендательного алгоритма.
Маск отметил: «Мы понимаем, что этот алгоритм пока несовершенен и требует серьезных доработок, но вы можете видеть, как мы работаем над его улучшением в реальном времени. Другие соцплатформы на такое не пойдут».
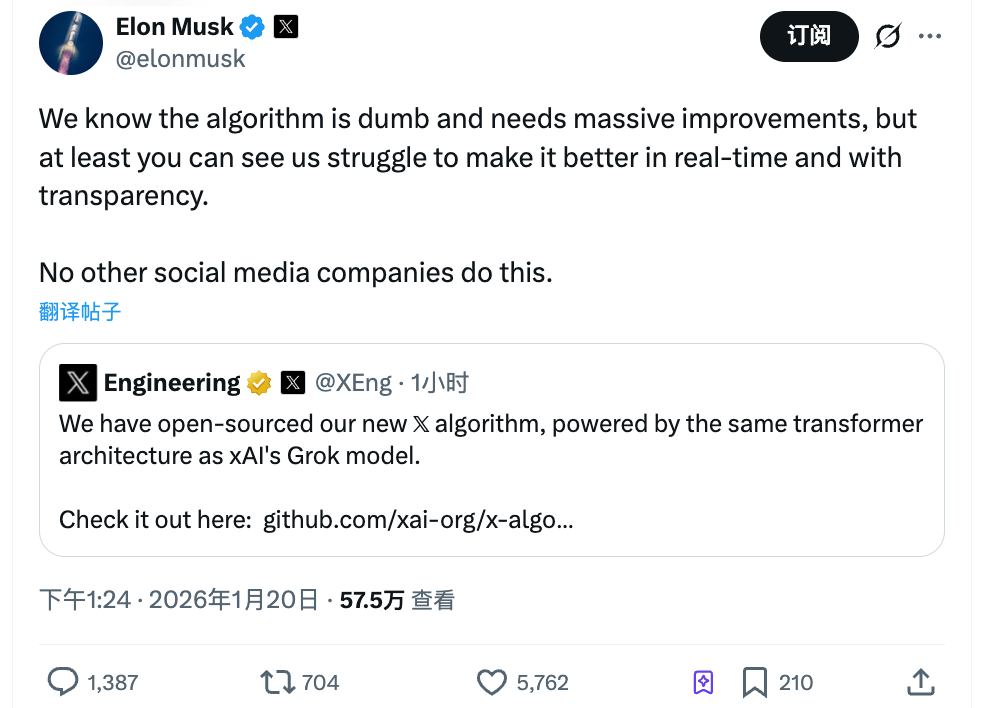
В его заявлении два ключевых момента: он признает недостатки алгоритма и делает ставку на прозрачность как основное преимущество.
Это второй случай открытия исходного кода алгоритма X. Версия 2023 года не обновлялась три года и уже не использовалась в продакшене. Сейчас код полностью переписан. Основная модель перешла от классического машинного обучения к трансформеру Grok. В официальном описании сказано: «ручная инженерия признаков полностью устранена».
Проще говоря: раньше инженеры вручную настраивали параметры алгоритма. Теперь ИИ напрямую анализирует вашу историю взаимодействий и решает, стоит ли показывать ваш контент.
Для авторов это значит, что стратегии вроде «лучшее время публикации» или «теги для роста подписчиков» больше не эффективны.
Мы также изучили открытый репозиторий на GitHub и с помощью ИИ нашли в коде несколько жестко заданных логик, которые заслуживают внимания.
Смена логики алгоритма: от ручных правил к ИИ-суждениям
Сначала разберем отличия между старой и новой версиями, чтобы избежать путаницы далее.
В 2023 году открытый алгоритм Twitter назывался Heavy Ranker. Это было классическое машинное обучение. Инженеры вручную задавали сотни признаков: наличие изображений, число подписчиков автора, давность публикации, наличие ссылок и т. д.
Каждому признаку присваивался вес, который постоянно корректировали для поиска лучшей комбинации.
Новая open-source версия называется Phoenix. Архитектура полностью иная — она гораздо больше опирается на крупные ИИ-модели. В основе — трансформер Grok, аналогичный тому, что лежит в ChatGPT и Claude.
В официальном README отмечено: «Мы устранили абсолютно все признаки, созданные вручную».
Старая система на ручных признаках полностью ушла.
Что теперь определяет качество контента?
Ответ: ваша модель поведения. Что вы лайкали, кому отвечали, на каких постах задерживались более двух минут, какие аккаунты блокировали. Phoenix передает эти действия трансформеру, и модель выявляет закономерности.
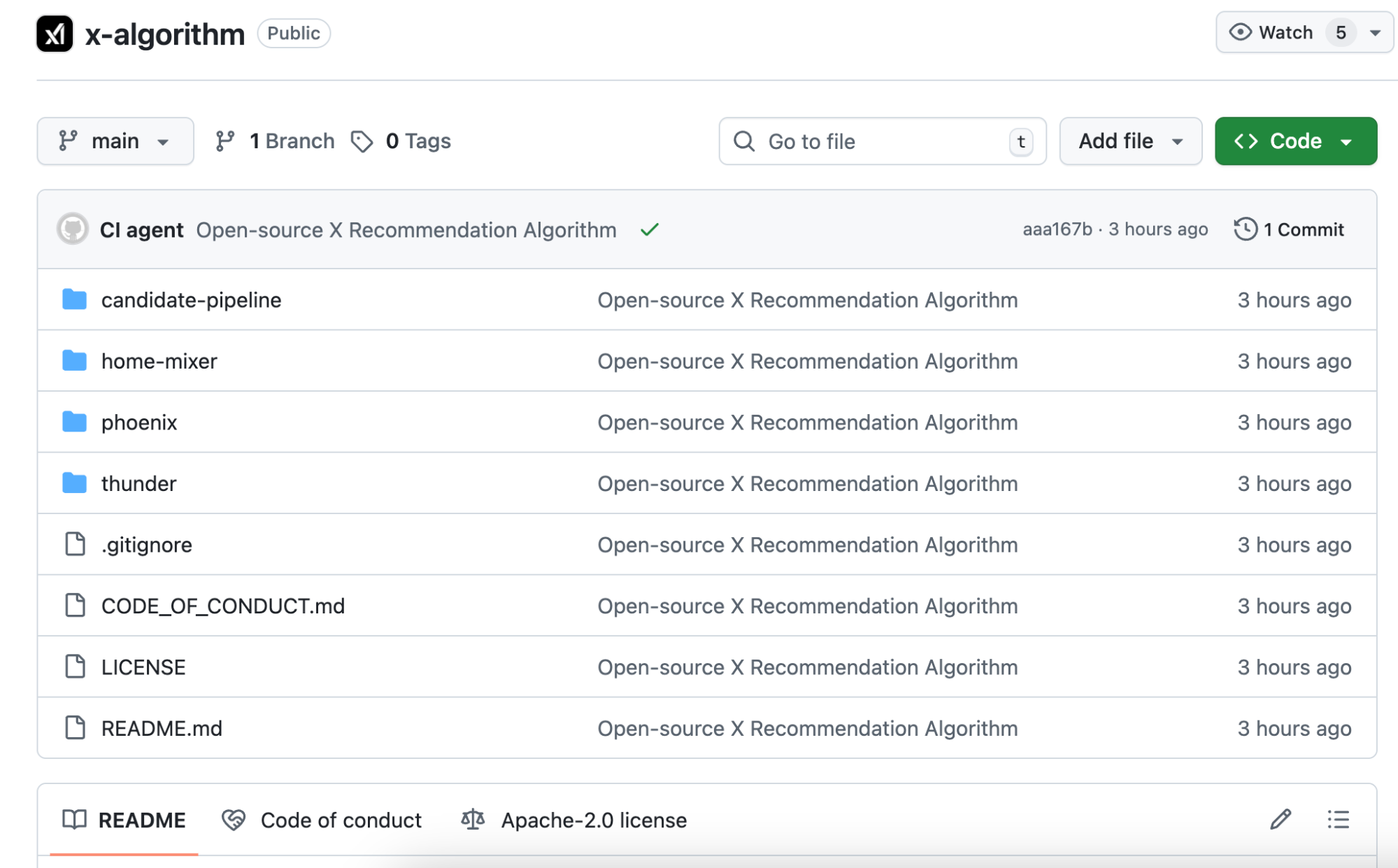
Для примера: старый алгоритм был как вручную составленная таблица баллов, где за каждый пункт начислялись очки.
Новый алгоритм — это ИИ, который анализирует всю вашу историю просмотров и предсказывает, что вы захотите увидеть дальше.
Для авторов это означает:
Во-первых, тактики «лучшее время публикации» или «золотые теги» практически теряют актуальность. Модель теперь ориентируется на индивидуальные предпочтения пользователя, а не на фиксированные признаки.
Во-вторых, продвижение контента зависит от того, «как пользователи реагируют на ваш контент». Эти реакции переводятся в 15 типов поведенческих прогнозов, о которых далее.
Алгоритм прогнозирует 15 типов пользовательских реакций
При оценке поста для рекомендаций Phoenix предсказывает 15 возможных пользовательских действий:
- Положительные: лайк, ответ, репост, цитата репоста, клик по посту, переход в профиль автора, просмотр более половины видео, раскрытие изображения, поделиться, задержка на определенное время, подписка на автора
- Отрицательные: «не интересно», блокировка автора, игнорирование автора, жалоба
Для каждого действия рассчитывается вероятность. Например, модель может оценить вероятность лайка в 60%, а блокировки — в 5%.
Алгоритм умножает каждую вероятность на соответствующий вес и суммирует для итогового балла.
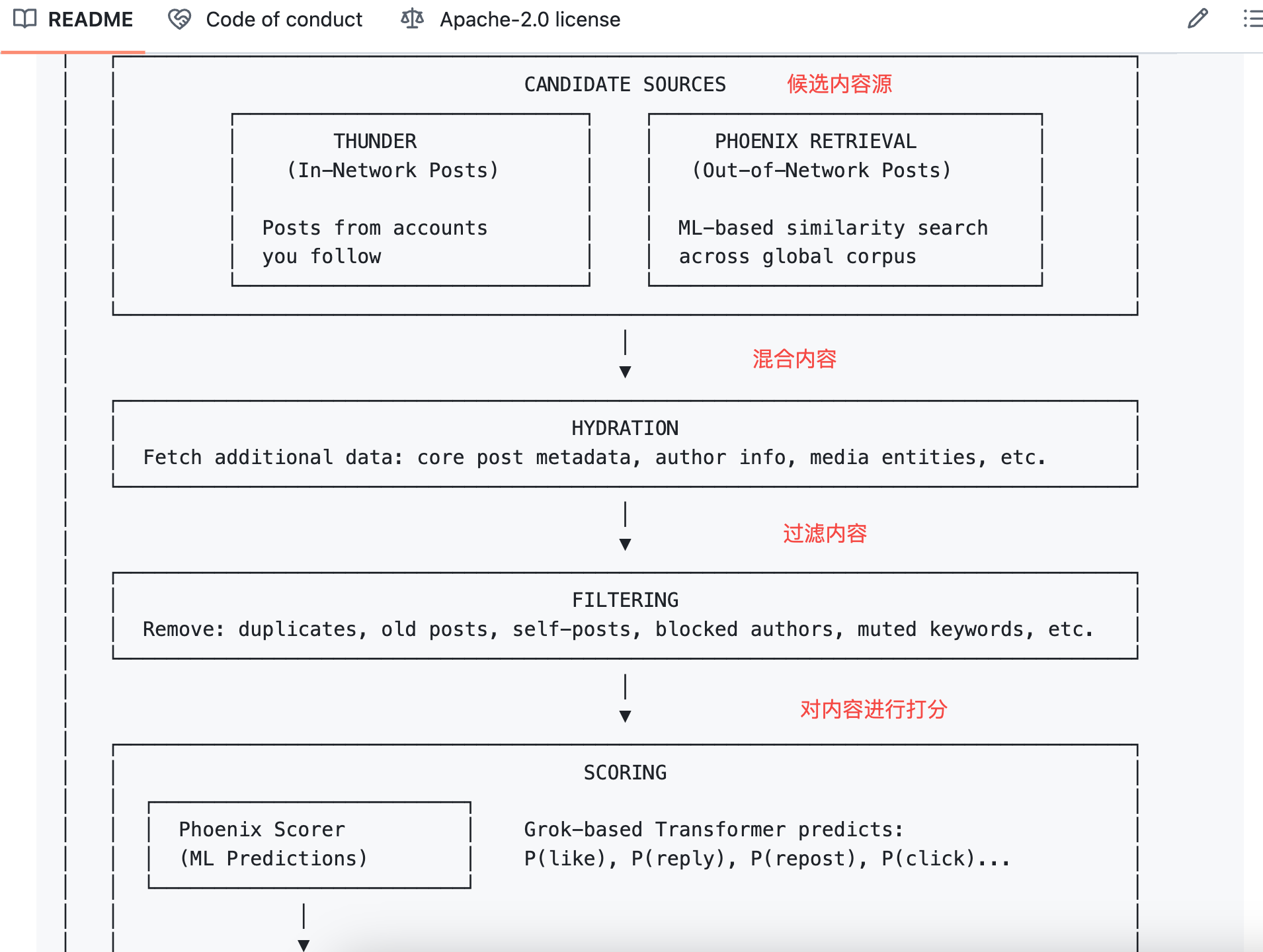
Формула:
Итоговый балл = Σ ( вес × P(действие) )
Положительные действия имеют положительные веса, отрицательные — отрицательные.
Посты с высокими итоговыми баллами поднимаются в рейтинге, с низкими — опускаются ниже.
На практике качество контента определяется не только его внутренними свойствами (читаемость и ценность по-прежнему обязательны для распространения), а тем, «какие реакции вызывает ваш контент». Алгоритм оценивает не сам контент, а поведение пользователей.
По этой логике, в отдельных случаях низкокачественный пост, вызвавший много ответов, может получить более высокий балл, чем качественный, но без вовлечения. Это и есть основная логика системы.
Однако новый open-source алгоритм не раскрывает точные веса для каждого поведения, а версия 2023 года их публиковала.
Старая версия: одна жалоба = 738 лайков
Рассмотрим данные за 2023 год. Хотя они устарели, они показывают, как алгоритм оценивает различные действия.
5 апреля 2023 года X опубликовала на GitHub таблицу весов.
Вот эти значения:
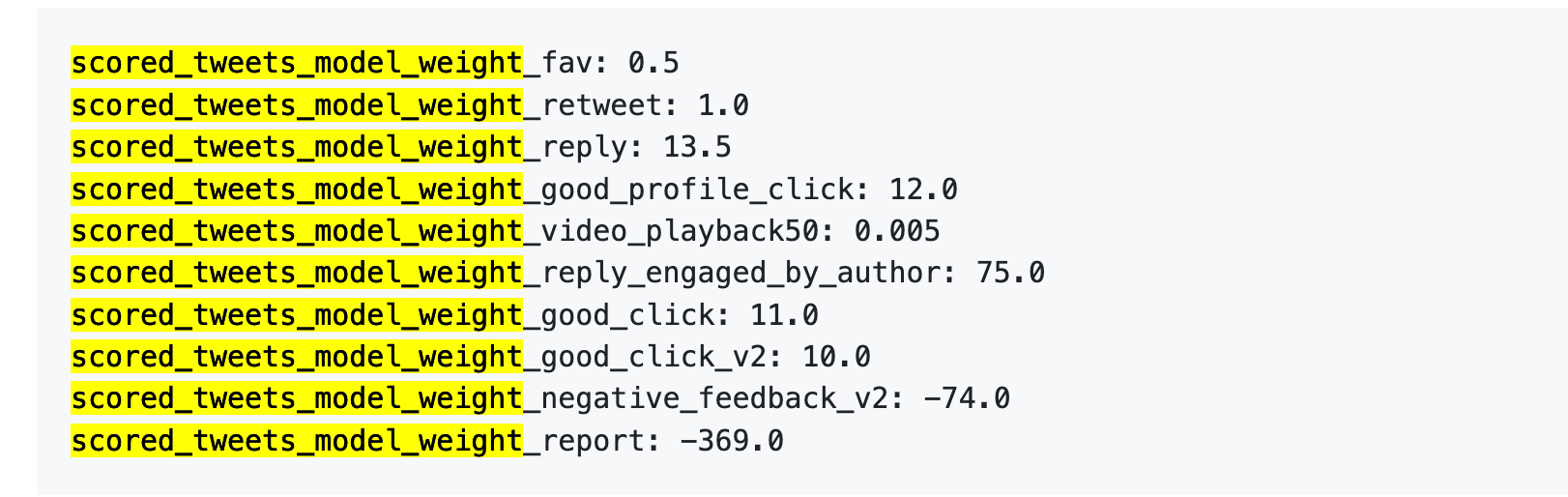
Проще говоря:
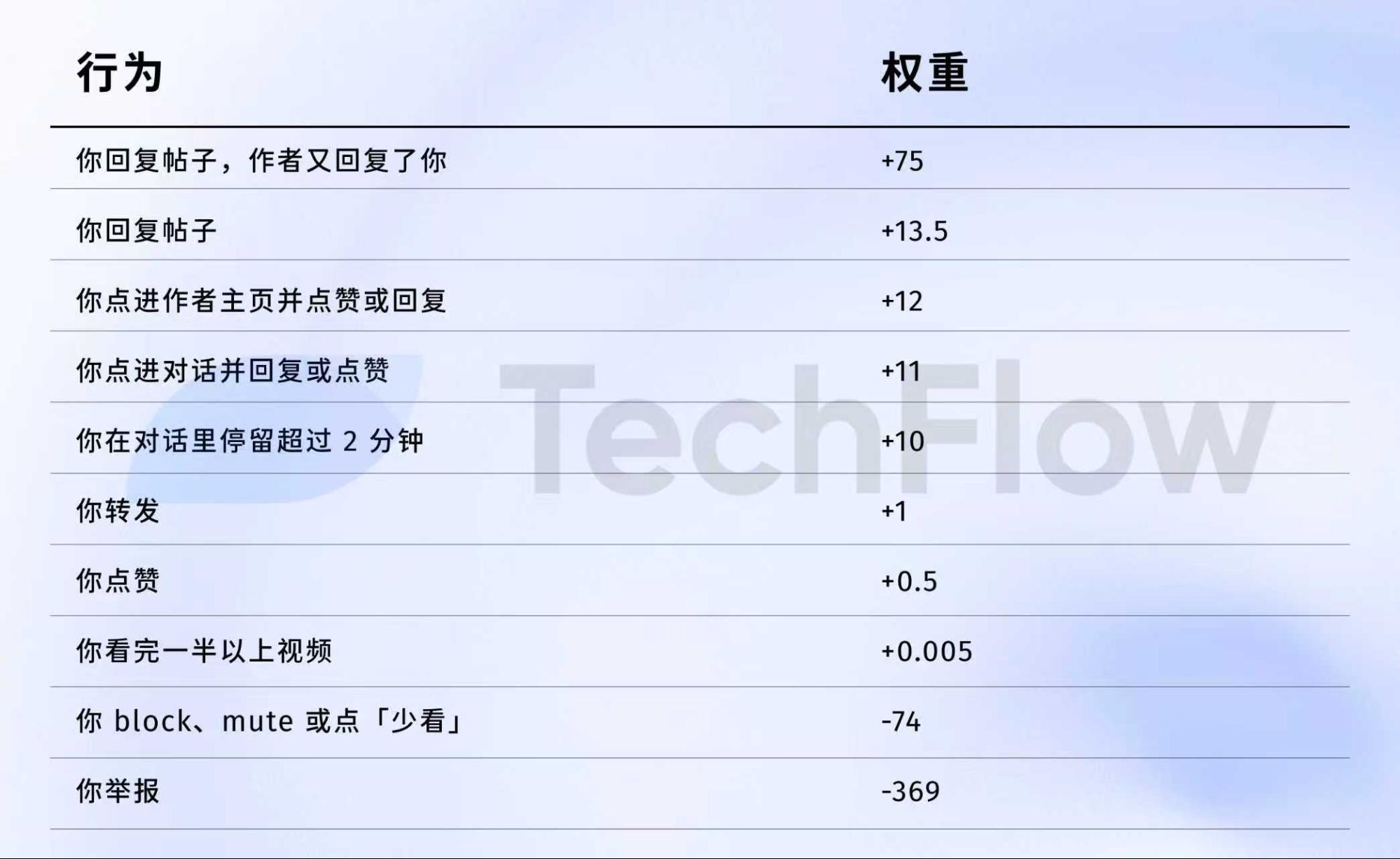
Источник: старая версия GitHub-репозитория twitter/the-algorithm-ml. Кликните для просмотра оригинального алгоритма.
Ключевые моменты:
Во-первых, лайки практически ничего не значат. Их вес — всего 0,5, минимальный среди положительных действий. Для алгоритма лайк почти не имеет значения.
Во-вторых, важнее всего диалог. «Вы отвечаете, и автор отвечает вам» — вес 75, в 150 раз больше лайка. Алгоритм гораздо выше ценит двустороннее общение, чем простые лайки.
В-третьих, негативные действия сильно штрафуют. Одна блокировка или игнорирование (-74) требует 148 лайков для компенсации. Одна жалоба (-369) требует 738 лайков. Эти минусовые баллы накапливаются в репутации аккаунта и влияют на распространение будущих постов.
В-четвертых, завершение просмотра видео почти не учитывается — вес всего 0,005. Это резко отличается от TikTok, где этот показатель ключевой.
В официальном документе также сказано: «Точные веса могут быть изменены в любой момент… Мы регулярно корректируем веса для оптимизации метрик платформы».
Веса можно менять в любой момент — и это происходит.
В новой версии конкретные значения не раскрываются, но логика та же: положительные действия прибавляют баллы, отрицательные — отнимают, итоговый балл — взвешенная сумма.
Числа могут меняться, но порядок важности, вероятно, тот же. Ответ на чужой комментарий ценнее 100 лайков. Блокировка хуже, чем отсутствие реакции.
Что авторам делать с этой информацией?
Изучив код новых и старых алгоритмов Twitter, можно сделать практические выводы:
1. Отвечайте на комментарии. В таблице весов «ответ автора комментатору» — самое ценное действие (+75), в 150 раз важнее лайка. Не нужно специально просить комментарии, но если вам пишут — отвечайте, даже простое «спасибо» учитывается алгоритмом.
2. Не провоцируйте блокировки. Одна блокировка требует 148 лайков для компенсации. Спорный контент может вызвать активность, но если это приводит к блокировкам, репутация аккаунта пострадает, и будущие посты будут распространяться хуже. Контроверсия — обоюдоострый меч, подумайте, прежде чем провоцировать.
3. Размещайте внешние ссылки в комментариях. Алгоритм не хочет, чтобы пользователи уходили с платформы. Ссылки в основном тексте наказываются — Маск это подтверждал публично. Если хотите привлечь трафик, публикуйте основной контент в посте, а ссылку — в первом комментарии.
4. Не спамьте. В новом коде есть Author Diversity Scorer, который штрафует за подряд идущие посты одного автора. Цель — разнообразить ленту, поэтому лучше опубликовать один качественный пост, чем десять подряд.
6. Больше нет «лучшего времени публикации». В старом алгоритме «время публикации» было ручным признаком, но Phoenix его убрал. Теперь Phoenix смотрит только на поведение пользователя, а не на время публикации. Стратегии вроде «вторник в 15:00» теперь неактуальны.
Это то, что можно извлечь из кода.
В публичной документации X есть также бонусные и штрафные правила, которых нет в этом релизе: верификация синим значком увеличивает охват, посты заглавными буквами штрафуются, а чувствительный контент снижает охват на 80%. Эти правила не открыты, поэтому здесь не рассматриваются.
В целом этот релиз open-source значителен.
В нем раскрыта архитектура системы, логика отбора контента, процесс оценки и ранжирования, различные фильтры. Код написан на Rust и Python, структура прозрачна, README подробнее многих коммерческих проектов.
Однако некоторые ключевые элементы отсутствуют.
1. Параметры весов не опубликованы. В коде лишь сказано, что «положительные действия прибавляют баллы, отрицательные — убавляют», но не указано, сколько стоит лайк или блокировка. В версии 2023 года были числа, сейчас — только формула.
2. Веса модели не раскрыты. Phoenix использует трансформер Grok, но параметры модели не включены. Видно, как вызывается модель, но не ее устройство.
3. Обучающие данные не опубликованы. Неясно, какие данные использовались для тренировки, как отбирались пользовательские действия, как формировались положительные и отрицательные примеры.
Иными словами, этот релиз open-source сообщает: «мы используем взвешенные суммы для расчета баллов», но реальные веса не раскрывает; говорит: «мы используем трансформеры для прогнозирования вероятностей поведения», но не показывает внутреннюю структуру трансформера.
Для сравнения: TikTok и Instagram не раскрывали даже такого объема информации. Открытие кода X действительно более масштабное, чем у других крупных платформ, но все же не полностью прозрачно.
Тем не менее, открытие кода ценно. Для авторов и исследователей возможность изучить код лучше, чем полное отсутствие доступа.
Заявление:
- Данная статья перепечатана с сайта [TechFlow], авторские права принадлежат оригинальному автору [David]. Если у вас есть вопросы по поводу перепечатки, пожалуйста, свяжитесь с командой Gate Learn, и команда оперативно рассмотрит обращение согласно действующим процедурам.
- Отказ от ответственности: Мнения и оценки, изложенные в статье, принадлежат исключительно автору и не являются инвестиционной рекомендацией.
- Другие языковые версии статьи переведены командой Gate Learn. Без явного упоминания Gate не копируйте, не распространяйте и не используйте переведенную статью.
Пригласить больше голосов


Похожие статьи

Все крипто ETF в США, о которых вам нужно знать в 2025 году

Рост и перспективы криптовалют следующего поколения на основе искусственного интеллекта

Как найти новые мемекоины до того, как они станут вирусными

Подъем XRP, обзор 9 проектов с соответствующими экосистемами

Pump.fun запускает собственный пул AMM? Очевидно, что целью является получение прибыли Raydium
