Mengenal Algoritma Rekomendasi Open-Source X: Konten Apa yang Benar-Benar Menarik Perhatian?
Pada sore hari tanggal 20 Januari, X secara terbuka merilis algoritma rekomendasi terbarunya.
Musk berkomentar: “Kami tahu algoritma ini masih kurang optimal dan membutuhkan banyak peningkatan, namun setidaknya Anda bisa melihat upaya kami memperbaikinya secara real time. Platform sosial lain tidak akan berani melakukan hal seperti ini.”
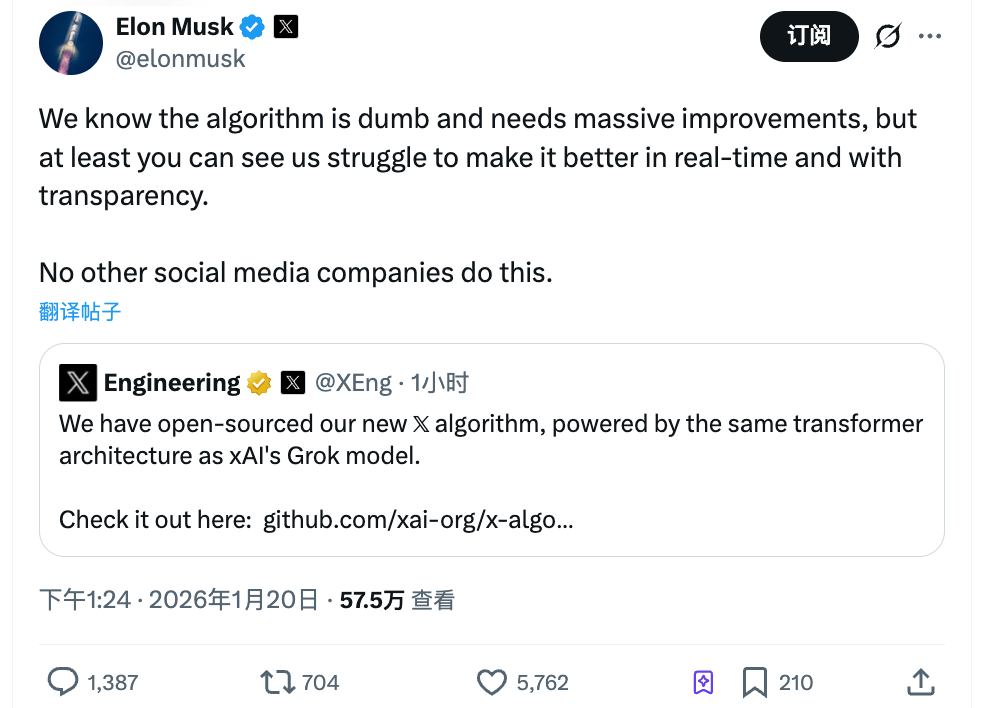
Pernyataan tersebut menyoroti dua hal. Pertama, ia mengakui kelemahan algoritma. Kedua, ia menjadikan transparansi sebagai nilai jual utama.
Ini merupakan kali kedua X membuka kode algoritmanya. Versi tahun 2023 sudah tiga tahun tanpa pembaruan dan telah terputus dari sistem produksi. Kali ini, kode sumber sepenuhnya ditulis ulang. Model inti beralih dari machine learning tradisional ke Grok transformer. Sesuai penjelasan resmi, “rekayasa fitur manual telah dihapus sepenuhnya.”
Secara sederhana: algoritma sebelumnya mengandalkan insinyur untuk mengatur parameter secara manual. Kini, AI langsung menganalisis riwayat interaksi Anda untuk menentukan apakah konten Anda layak dipromosikan.
Bagi kreator, hal ini berarti strategi seperti “waktu posting optimal” atau “tag yang meningkatkan pengikut” bisa jadi tidak lagi efektif.
Kami juga menelusuri repositori GitHub open-source dan, dengan bantuan AI, menemukan beberapa logika hard-coded dalam kode yang menarik untuk dieksplorasi.
Pergeseran Logika Algoritma: Dari Aturan Manual ke Penilaian Berbasis AI
Pertama, mari kita bedakan versi lama dan baru agar diskusi berikutnya lebih jelas.
Pada tahun 2023, algoritma open-source Twitter bernama Heavy Ranker. Algoritma ini berbasis machine learning tradisional. Insinyur secara manual mendefinisikan ratusan fitur: apakah postingan berisi gambar, jumlah pengikut penulis, waktu posting, apakah mengandung tautan, dan sebagainya.
Setiap fitur diberikan bobot, yang terus disesuaikan untuk menemukan kombinasi paling efektif.
Versi open-source terbaru disebut Phoenix. Arsitekturnya sepenuhnya berbeda—lebih mengandalkan model AI berskala besar. Model intinya memakai Grok transformer, teknologi yang juga digunakan oleh ChatGPT dan Claude.
README resmi menyatakan: “Kami telah menghapus seluruh fitur yang direkayasa secara manual.”
Sistem berbasis aturan yang mengandalkan ekstraksi fitur konten secara manual kini benar-benar dihilangkan.
Lalu, apa yang menjadi dasar penilaian algoritma terhadap kualitas konten?
Jawabannya: urutan perilaku pengguna. Apa yang Anda sukai, kepada siapa Anda membalas, postingan mana yang Anda baca lebih dari dua menit, jenis akun mana yang Anda blokir. Phoenix mengolah perilaku ini ke dalam transformer, membiarkan model mempelajari dan merangkum polanya.
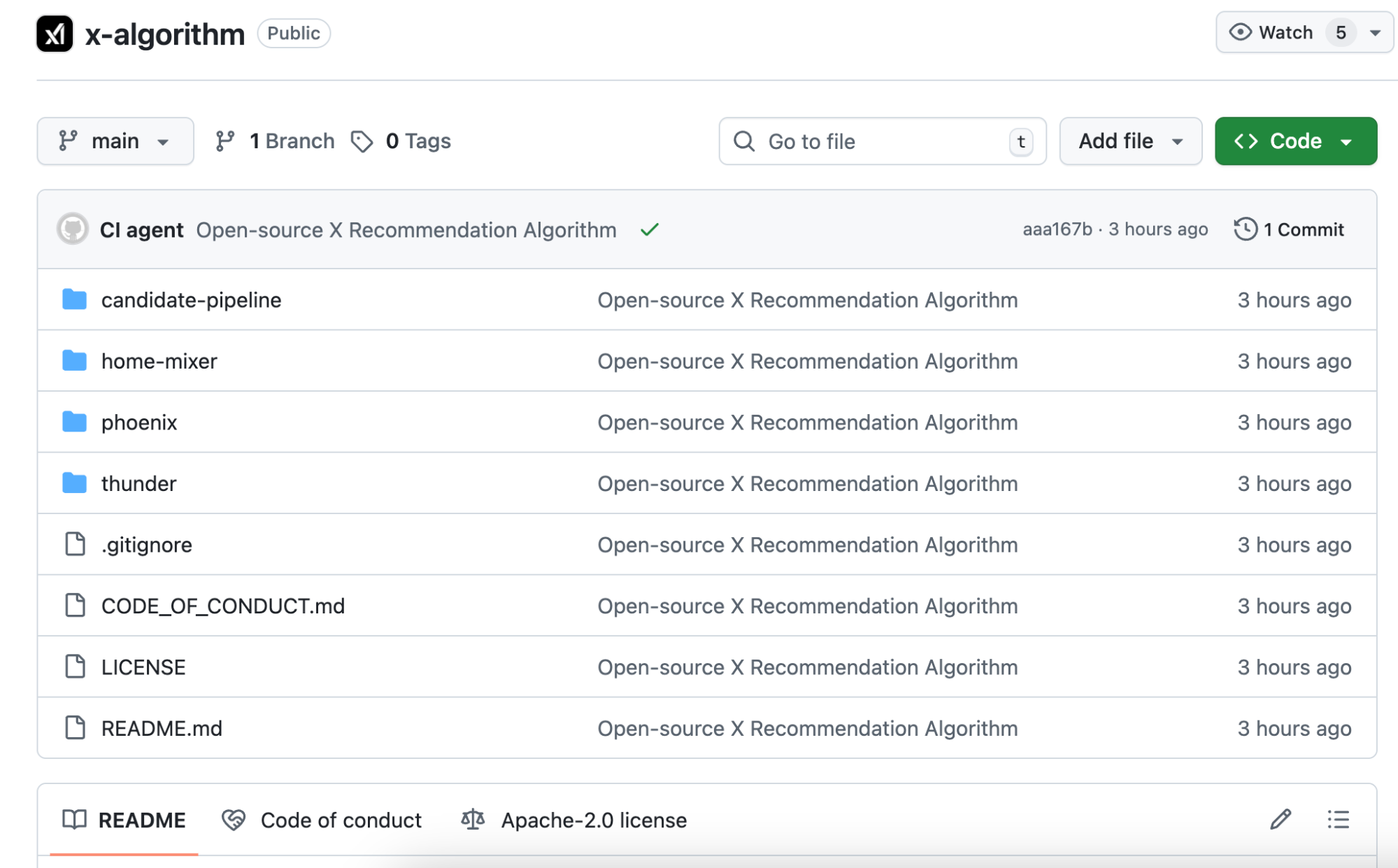
Ilustrasinya: algoritma lama seperti lembar skor manual, memberi nilai untuk setiap kriteria yang terpenuhi.
Algoritma baru ibarat AI yang mengakses seluruh riwayat penelusuran Anda, lalu memprediksi apa yang ingin Anda lihat berikutnya.
Bagi kreator, hal ini berarti dua hal:
Pertama, strategi seperti “waktu posting terbaik” atau “tag emas” kini jauh berkurang nilainya. Model tidak lagi mengacu pada fitur tetap, melainkan preferensi personal setiap pengguna.
Kedua, promosi konten Anda lebih ditentukan oleh “bagaimana pengguna bereaksi terhadap konten Anda.” Reaksi tersebut dikonversi menjadi 15 jenis prediksi perilaku, yang akan dijelaskan berikutnya.
Algoritma Memprediksi 15 Jenis Reaksi Pengguna
Saat Phoenix mengevaluasi sebuah postingan untuk direkomendasikan, algoritma memprediksi 15 kemungkinan aksi pengguna:
- Aksi positif: suka, balas, repost, kutip repost, klik postingan, klik profil penulis, menonton lebih dari setengah video, memperbesar gambar, membagikan, membaca dalam waktu tertentu, mengikuti penulis
- Aksi negatif: pilih “tidak tertarik,” blokir penulis, bisukan penulis, laporkan
Setiap aksi memiliki probabilitas prediksi. Misalnya, model memperkirakan peluang Anda menyukai sebuah postingan sebesar 60% dan peluang Anda memblokir penulis sebesar 5%.
Algoritma mengalikan setiap probabilitas dengan bobotnya, lalu menjumlahkan untuk mendapatkan skor akhir.
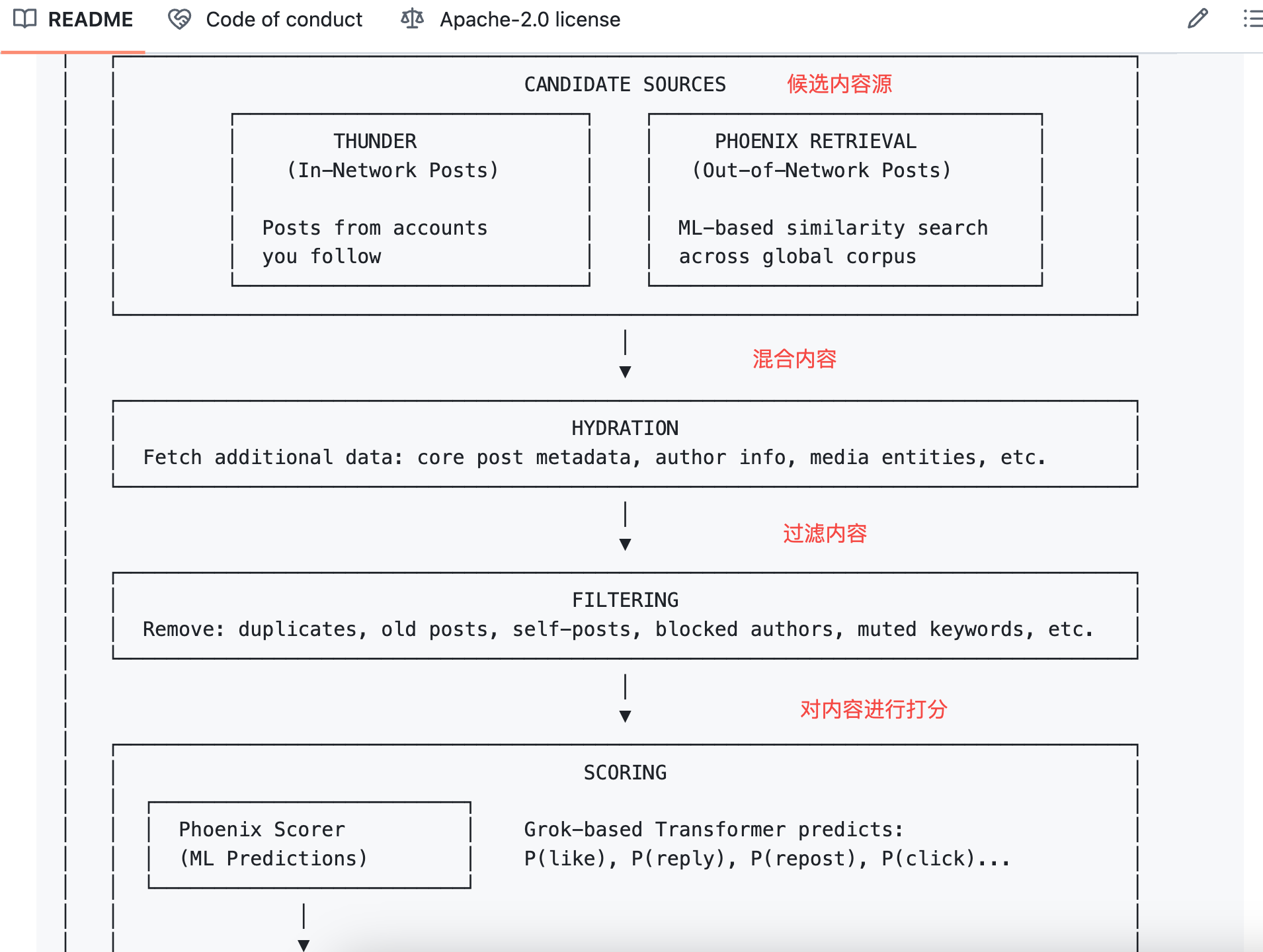
Rumusnya:
Skor Akhir = Σ ( bobot × P(aksi) )
Aksi positif berbobot positif; aksi negatif berbobot negatif.
Postingan dengan skor total tinggi akan naik peringkat; yang skornya rendah akan turun.
Secara praktik, kualitas konten “baik” kini tidak lagi hanya ditentukan oleh mutu intrinsiknya (meski keterbacaan dan nilai tetap jadi syarat utama untuk dibagikan). Penentu utamanya adalah “reaksi yang dipicu oleh konten Anda.” Algoritma tidak memperhatikan isi konten, melainkan perilaku pengguna.
Dengan logika ini, dalam kasus ekstrem, postingan berkualitas rendah yang memicu banyak balasan bisa mendapat skor lebih tinggi daripada konten berkualitas tinggi tanpa interaksi. Inilah logika dasar sistem tersebut.
Namun, algoritma open-source terbaru tidak mempublikasikan bobot spesifik untuk tiap perilaku, sementara versi 2023 pernah melakukannya.
Referensi Versi Lama: Satu Laporan = 738 Suka
Berikut data tahun 2023. Meski sudah tidak relevan, data ini membantu menggambarkan bagaimana algoritma menilai tiap aksi.
Pada 5 April 2023, X merilis data bobot di GitHub.
Berikut angkanya:
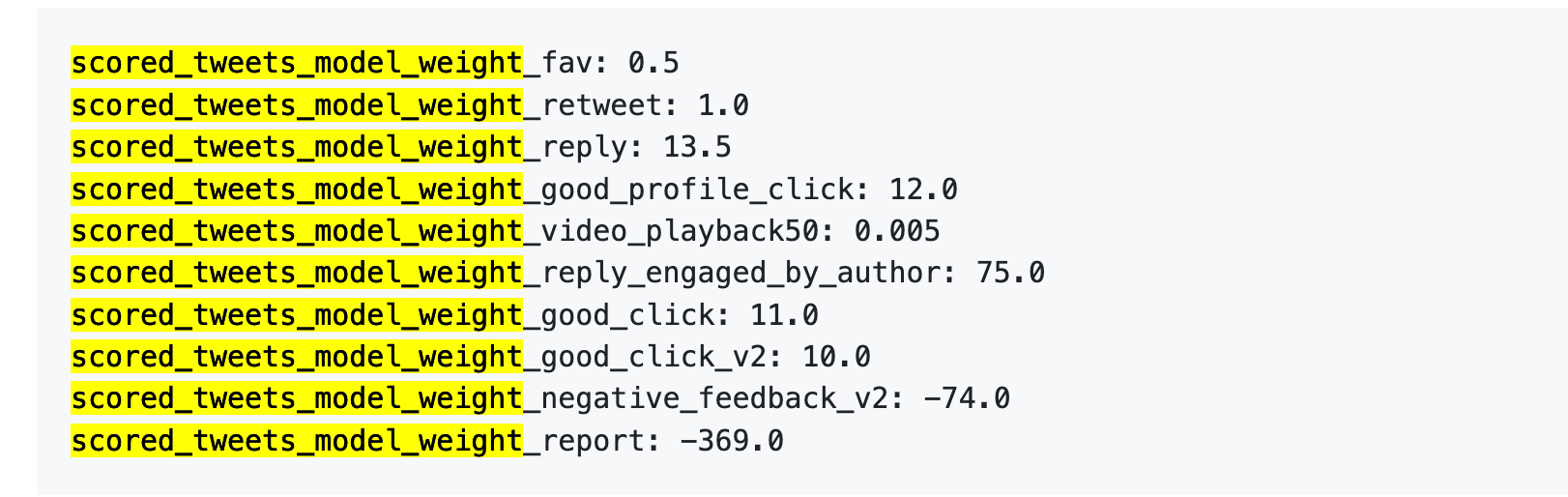
Secara sederhana:
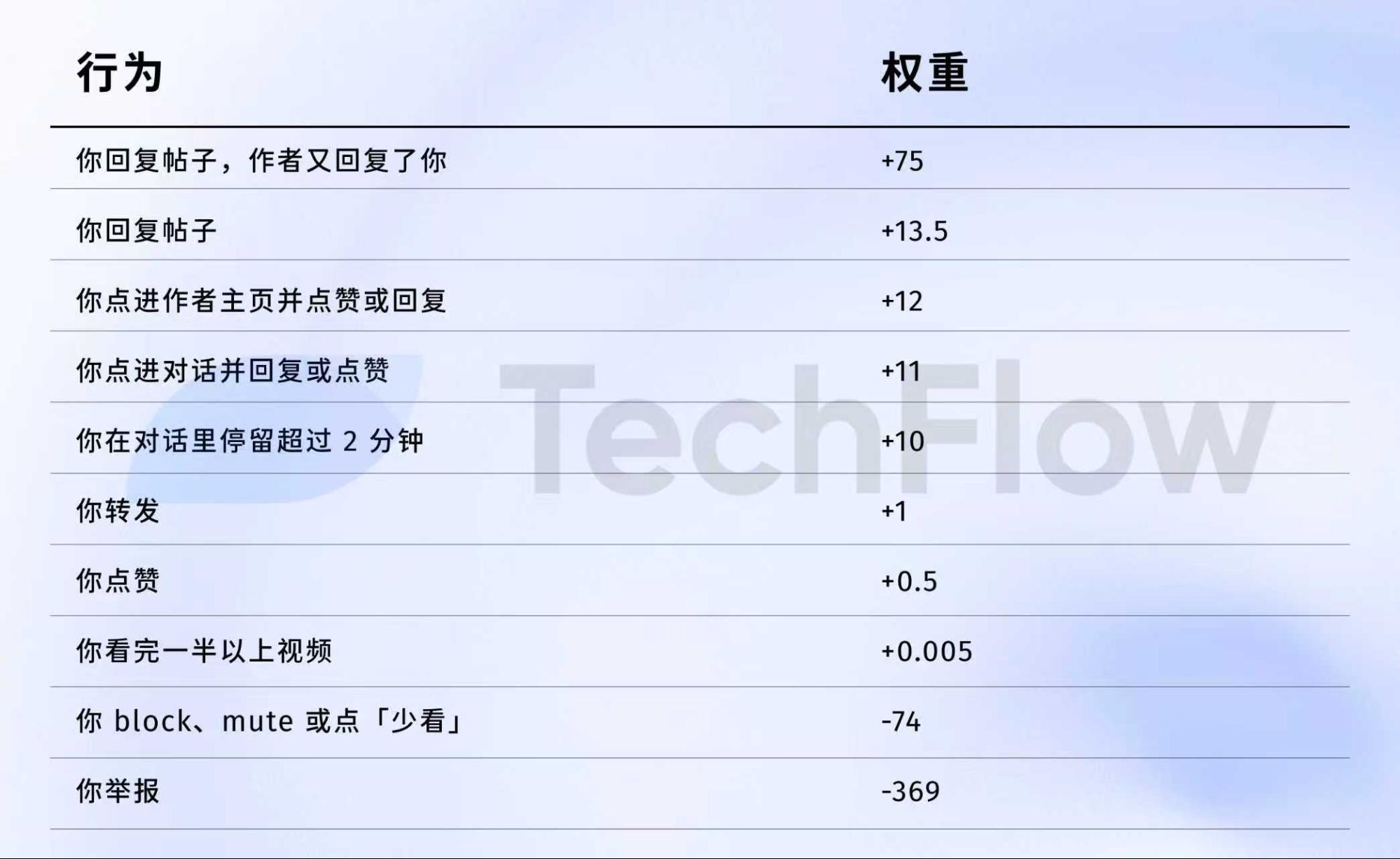
Sumber data: Versi lama Repositori GitHub twitter/the-algorithm-ml. Klik untuk melihat algoritma asli.
Beberapa angka penting:
Pertama, “suka” hampir tidak bernilai. Bobotnya hanya 0,5, terendah di antara aksi positif. Algoritma menganggap “suka” hampir tidak berharga.
Kedua, percakapan sangat penting. “Anda membalas dan penulis membalas kembali” memiliki bobot 75—150 kali lipat dari “suka.” Algoritma jauh lebih menghargai interaksi dua arah daripada hanya “suka.”
Ketiga, umpan balik negatif membawa penalti berat. Satu blokir atau bisukan (-74) membutuhkan 148 “suka” untuk menetralkan. Satu laporan (-369) membutuhkan 738 “suka.” Skor negatif ini terakumulasi pada reputasi akun Anda, memengaruhi distribusi postingan di masa depan.
Keempat, tingkat penyelesaian video berbobot sangat rendah—hanya 0,005, hampir tak berarti. Ini sangat kontras dengan platform seperti TikTok, yang menjadikan tingkat penyelesaian sebagai metrik utama.
Dokumen resmi juga menyatakan: “Bobot dalam file dapat diubah kapan saja… Kami secara berkala menyesuaikan bobot untuk mengoptimalkan metrik platform.”
Bobot dapat berubah sewaktu-waktu—dan memang sudah berubah.
Versi terbaru tidak mengungkap nilai spesifik, tetapi kerangka logika dalam README tetap sama: aksi positif menambah poin, aksi negatif mengurangi, dan skor akhir merupakan jumlah berbobot.
Angka pastinya bisa berubah, namun urutan relatif kemungkinan besar tetap. Membalas komentar orang lain lebih bernilai daripada mendapat 100 “suka.” Diblokir lebih buruk daripada tidak mendapat interaksi sama sekali.
Apa yang Sebaiknya Dilakukan Kreator dengan Informasi Ini?
Setelah menelaah kode algoritma Twitter versi lama dan baru, berikut beberapa langkah yang dapat diambil:
1. Balas komentar dari pengikut Anda. Dalam tabel bobot, “penulis membalas komentar” adalah aksi dengan skor tertinggi (+75), 150 kali lebih bernilai daripada “suka.” Anda tidak perlu meminta komentar, namun selalu balas jika ada yang berkomentar—bahkan ucapan “terima kasih” pun dihitung oleh algoritma.
2. Hindari membuat pengguna ingin memblokir Anda. Satu blokir membutuhkan 148 “suka” untuk menetralkan. Konten kontroversial bisa meningkatkan interaksi, namun jika interaksi itu berupa “orang ini mengganggu, blokir,” reputasi akun Anda akan terkena dampak jangka panjang, memengaruhi distribusi postingan ke depannya. Kontroversi adalah pedang bermata dua—pertimbangkan sebelum memprovokasi.
3. Tempatkan tautan eksternal di kolom komentar. Algoritma tidak ingin pengguna meninggalkan platform. Menyisipkan tautan di teks utama akan dikenai penalti—Musk telah mengonfirmasi hal ini secara publik. Jika Anda ingin mengarahkan trafik, letakkan konten utama di postingan dan tautan di komentar pertama.
4. Jangan spam. Kode baru mencakup Author Diversity Scorer yang memberi penalti pada postingan berurutan dari penulis yang sama. Tujuannya untuk mendiversifikasi feed pengguna, sehingga lebih baik memposting satu konten berkualitas daripada sepuluh secara beruntun.
6. Tidak ada lagi “waktu posting terbaik.” Algoritma lama menggunakan “waktu posting” sebagai fitur manual, namun Phoenix telah menghapusnya. Phoenix hanya melihat perilaku pengguna, bukan waktu posting. Jadi strategi “Selasa jam 3 sore” kini semakin tidak relevan.
Inilah yang dapat disimpulkan dari kode tersebut.
Ada juga aturan bonus dan penalti dalam dokumentasi publik X yang tidak tercantum dalam rilis open-source ini: verifikasi centang biru meningkatkan jangkauan, postingan dengan huruf kapital seluruhnya dikenai penalti, dan konten sensitif memicu pengurangan jangkauan hingga 80%. Aturan ini tidak di-open-source, sehingga tidak dibahas di sini.
Secara keseluruhan, rilis open-source ini sangat substantif.
Arsitektur sistem lengkap, logika recall kandidat konten, proses penilaian dan pemeringkatan, serta berbagai filter semuanya tersedia. Kode utama ditulis dalam Rust dan Python, dengan struktur jelas serta README yang lebih detail dibandingkan banyak proyek komersial.
Namun, ada beberapa elemen kunci yang belum dipublikasikan.
1. Parameter bobot tidak tersedia publik. Kode hanya menjelaskan bahwa “aksi positif menambah poin, aksi negatif mengurangi,” namun tidak merinci nilai “suka” atau “blokir.” Versi 2023 setidaknya mengungkapkan angka; kali ini hanya kerangka rumus yang tersedia.
2. Bobot model tidak tersedia publik. Phoenix menggunakan Grok transformer, namun parameter model tidak disertakan. Anda hanya bisa melihat cara model dipanggil, bukan mekanisme internalnya.
3. Data pelatihan tidak tersedia publik. Tidak jelas data apa yang digunakan untuk melatih model, bagaimana perilaku pengguna diambil sampelnya, atau bagaimana sampel positif dan negatif dibangun.
Dengan kata lain, rilis open-source ini hanya menjelaskan “kami menggunakan penjumlahan berbobot untuk menghitung skor,” namun tidak bobot aktualnya; menjelaskan “kami memakai transformer untuk memprediksi probabilitas perilaku,” tetapi tidak seperti apa transformer di dalamnya.
Dibandingkan TikTok dan Instagram, X telah merilis lebih banyak detail. Rilis open-source X memang lebih komprehensif daripada platform besar lainnya, tetapi tetap belum sepenuhnya transparan.
Namun, open-source tetap bernilai. Bagi kreator dan peneliti, bisa meninjau kode jauh lebih baik daripada tidak memiliki akses sama sekali.
Pernyataan:
- Artikel ini merupakan reprint dari [TechFlow], dengan hak cipta milik penulis asli [David]. Jika Anda memiliki keberatan terkait reprint ini, silakan hubungi tim Gate Learn, dan tim akan menindaklanjuti sesuai prosedur yang berlaku.
- Disclaimer: Pandangan dan opini dalam artikel ini sepenuhnya milik penulis dan tidak merupakan saran investasi.
- Versi bahasa lain dari artikel ini diterjemahkan oleh tim Gate Learn. Tanpa penyebutan eksplisit Gate, dilarang menyalin, mendistribusikan, atau menjiplak artikel terjemahan ini.
Bagikan


Artikel Terkait

Bagaimana cara menemukan memecoin baru sebelum mereka menjadi viral

Lonjakan XRP, Tinjauan 9 Proyek dengan Ekosistem Terkait

Naik dan Prospek Mata Uang Kripto AI Generasi Berikutnya

Setiap ETF Kripto AS yang Harus Anda Ketahui pada Tahun 2025

Mengapa Anda Terus Kehilangan Saat Membeli Memes? Analisis Komprehensif Tentang Manipulasi Pasar di Balik Memes
